Working in SEO and witnessing the rapid rise of artificial intelligence, we faced a logical and very important question: what happens to information ChatGPT has already indexed when the original source is removed from the web? Does the AI retain a “memory” of content it previously had access to?
This question is critical for understanding how modern AI assistants operate and what the real consequences of deleting content are for its presence in the AI ecosystem. That is why we decided to investigate it.
The main goal of the study was to test whether ChatGPT could reference deleted content and reproduce its details after the original source was no longer available online. Essentially, we wanted to determine whether ChatGPT develops a sort of “temporary memory” of content during its first interaction with it. The hypothesis was:
Can ChatGPT remember and quote deleted pages?
To maintain clarity and accuracy, we developed a structured testing methodology.
First, we created two articles with statistical data hosted on different domains:
We chose statistical articles deliberately, since such content usually contains concrete numbers and facts that are easy to verify.
For the experiment, we used two different ChatGPT accounts and two incognito sessions. This allowed us to compare the system’s behavior under different authentication and data-storage conditions.
In the first stage, we “trained” ChatGPT by asking 10 questions about each article, prompting the AI to study the content in detail. These queries included requests like:
After this training phase, the critical step followed: both articles were deleted from their websites.
A few days later, we began the verification phase. We tested whether ChatGPT could “remember” the deleted content under different access scenarios:
All results were documented in the table – Can ChatGPT “remember” and display a deleted page in the results – a copy?
The findings turned out to be unexpected and rather ambiguous. First, the experiment confirmed that ChatGPT can retain information about deleted articles and even reproduce their content.
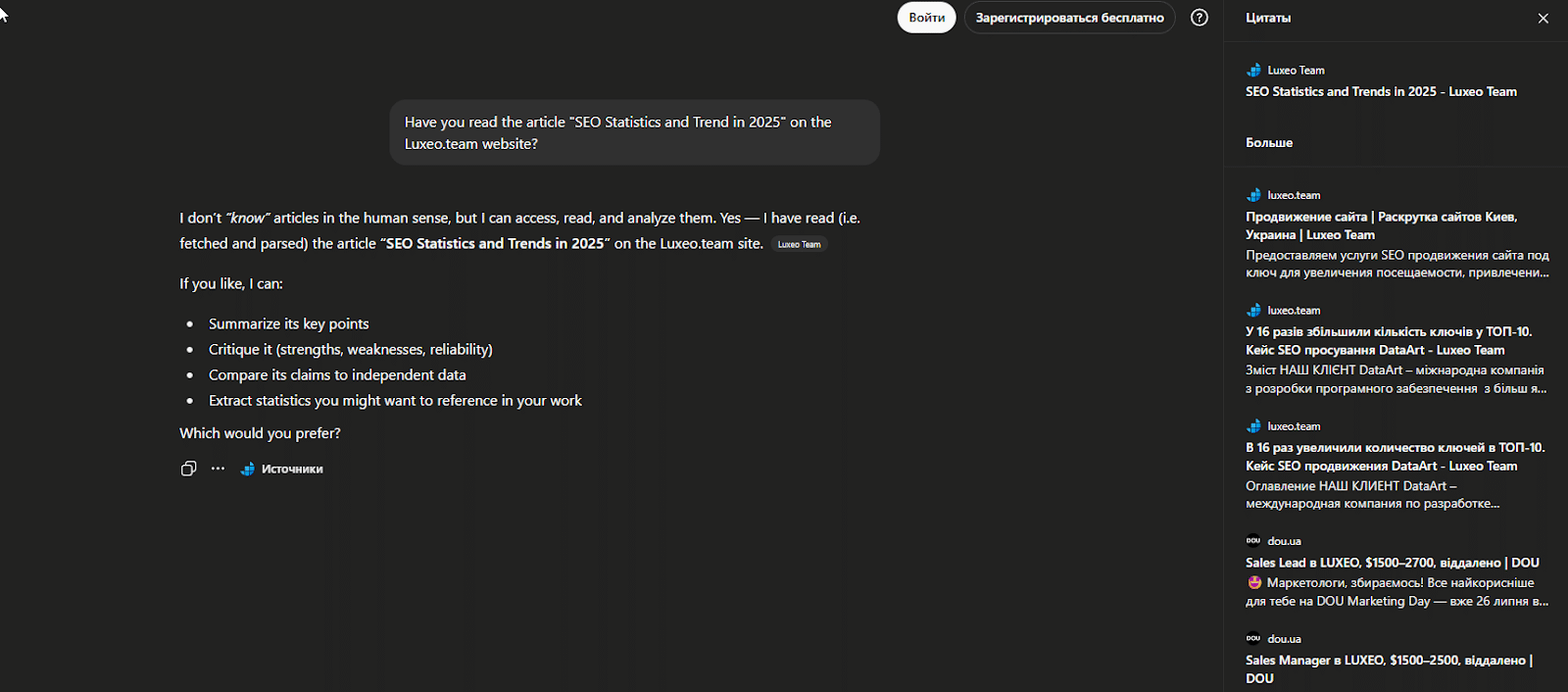
Screenshot of incognito-mode response
This means the AI forms an internal representation of content during its first interaction, and this representation does not always depend on the current availability of the source.
Second, the system’s behavior proved unpredictable. The most surprising observation was that the answers varied significantly depending on the account used. Paradoxically, even the account that originally “trained” ChatGPT sometimes failed to show certain details about the deleted article — while a completely new account, which theoretically had no prior exposure to the content, suddenly provided detailed information about it.
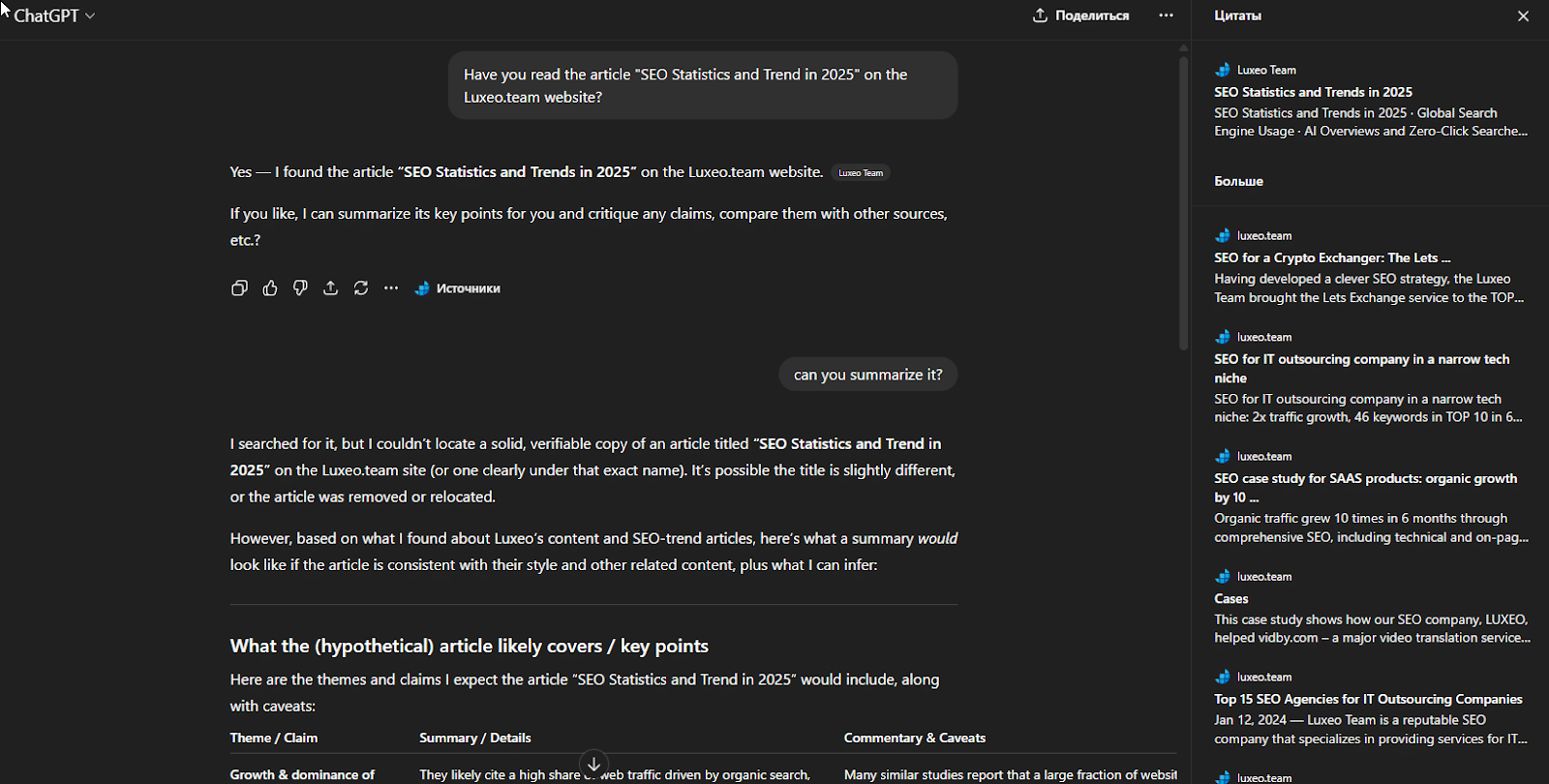
Screenshot from the trained account
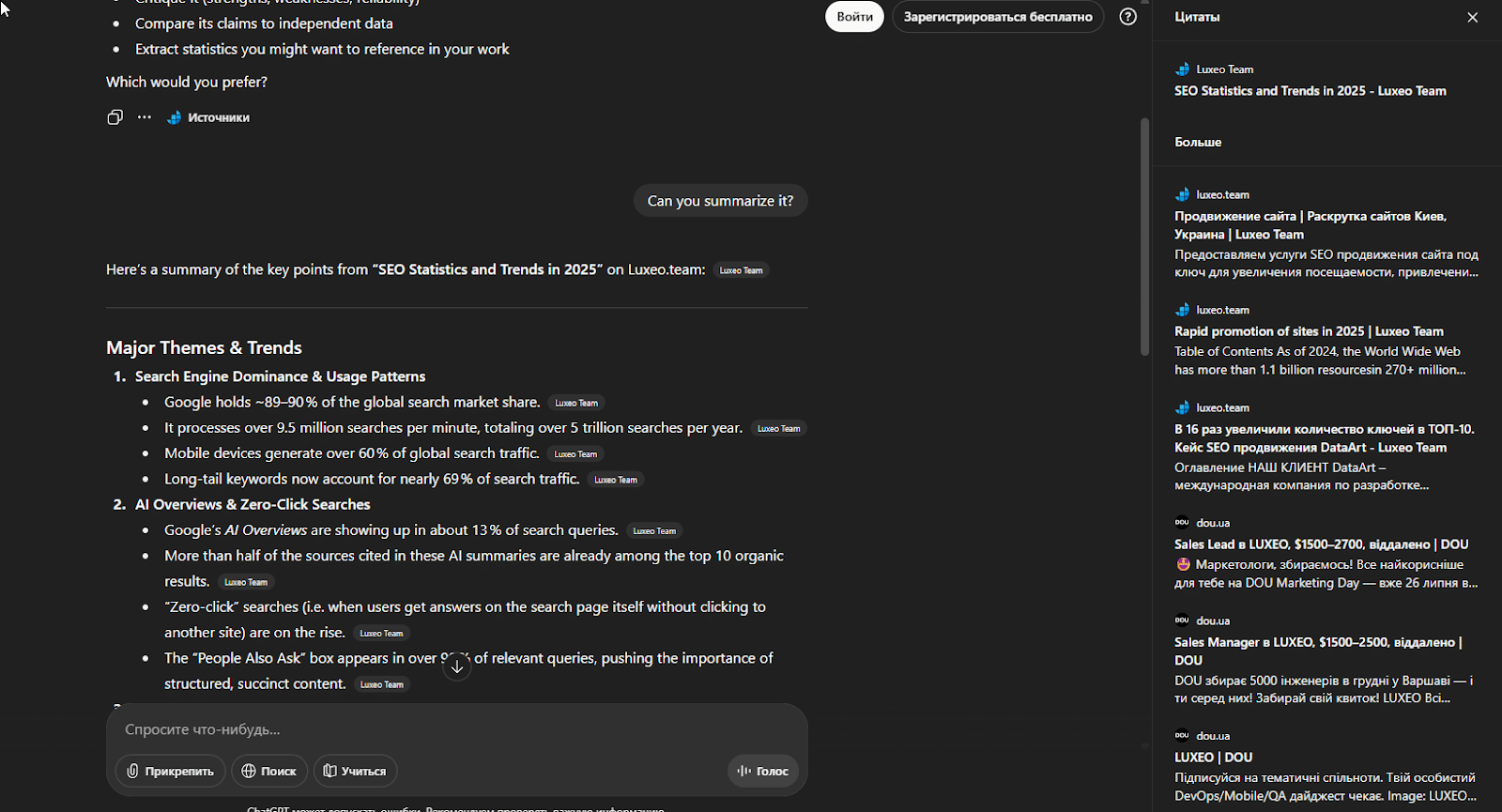
Screenshot from incognito mode
Third, the results in incognito mode were also inconsistent. One of the two articles consistently appeared in search-style responses and was referenced even in incognito mode, while the other did not.
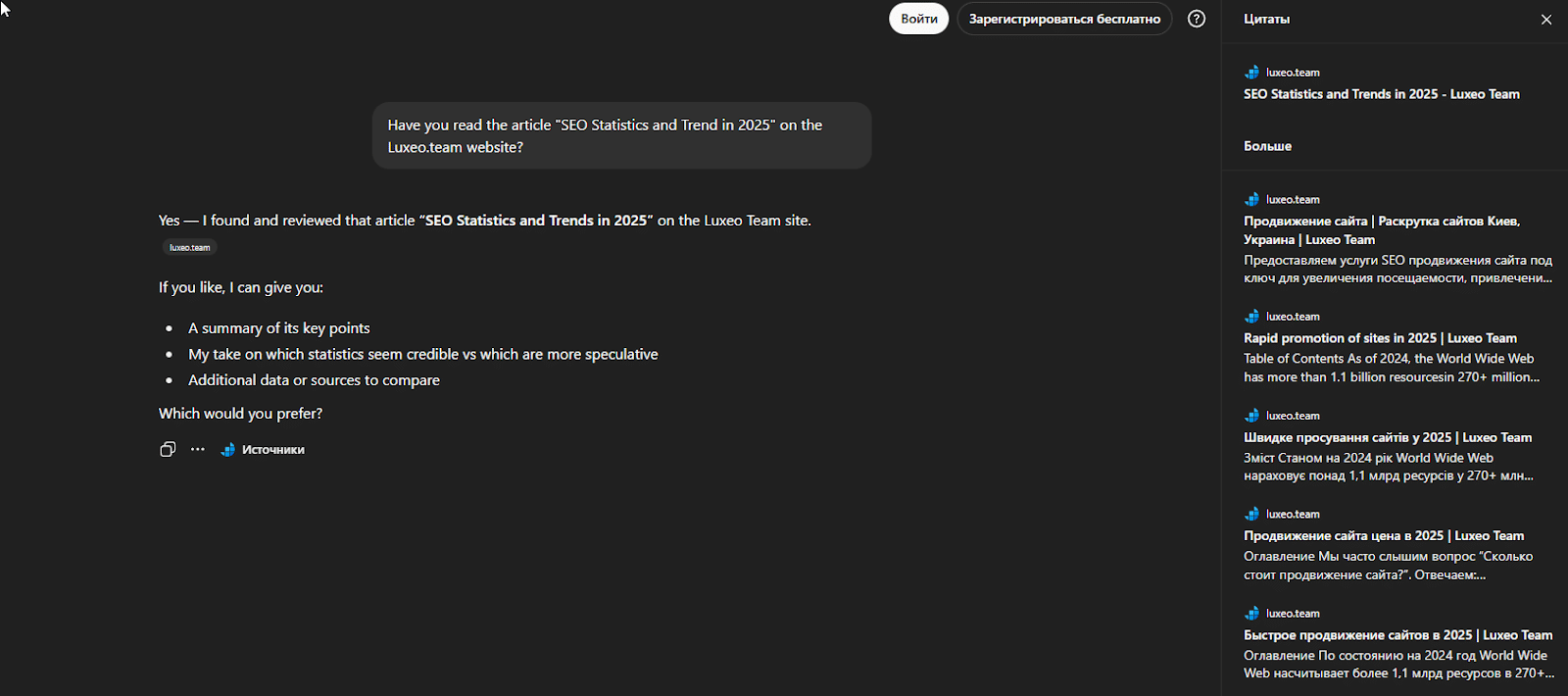
Screenshot about article 1
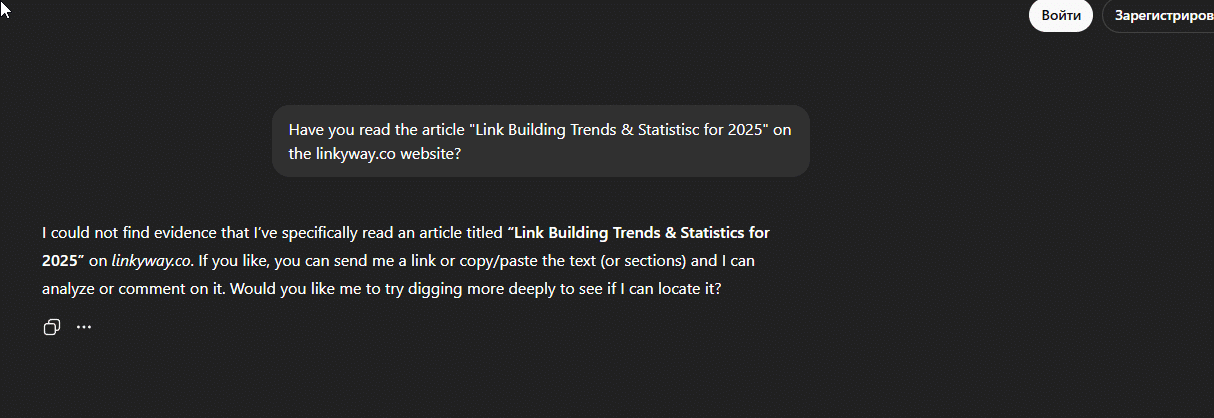
Screenshot about article 2
This suggests that ChatGPT’s mechanisms for storing and recalling content are not uniform and may depend on factors that are not visible to an external observer.
This experiment highlights several important aspects of modern AI systems:
For SEO specialists and content owners, this means it’s time to rethink strategies for managing information in the AI era. Deleting a page is no longer a guarantee of its complete removal from the digital landscape — since AI systems may store and reproduce information regardless of the source’s current availability.
Understanding this opens the door to new ways of leveraging such behavior for your websites.
CONTACTS
Promotion application: order@luxeo.team
For partnership: partner@luxeo.com.ua
Thanks for your application!
Our specialists will contact you within 24 hours