Реальное значение файла llms.txt для систем LLM: Результаты независимого теста AI отповедей №3
24 Сентября 2025123 просмотров
1 мин.
Dmytro Kovshun
Редактор, писатель
Оглавление
В последние месяцы активно раскручивается тезис, что наличие llms.txt почти гарантированно приводит к тому, что вы попадёте в ответы в LLM (Large Language Models). Об этом пишут в блогах, это рекомендуют нишевые инфлюенсеры, и это включают в оффер для клиентов компании, которые предлагают AEO услуги. Но так ли это на самом деле?
Llms.txt позиционируется как стандарт, предоставляющий LLM-системам карту важного контента сайта. Но на данный момент нет подтверждений, действительно ли AI-модели его используют. Мы видели много информации, но не видели реальных фактов того, что llms.txt работает.
Несколько фактов о файле и почему о нём заговорили:
llms.txt — это текстовый файл, размещённый в корне домена (например, https://example.com/llms.txt), который в формате Markdown или с похожими пометками содержит перечень URL-адресов или описаний страниц, которые владельцы сайта считают «ключевыми», «качественными» и такими, что стоит указать LLM-системам как приоритетный контент.
Инициатива llms.txt пока является предложением стандарта; она не является официально подтверждённой повсеместно используемой практикой со стороны крупнейших языковых моделей или компаний, но тем не менее активно обсуждается в SEO-сообществе. По данным интервью и публичных заявлений, ни один из крупных поставщиков языковых моделей (OpenAI / ChatGPT, Anthropic / Claude, Google / Gemini и т.д.) официально не подтвердил, что он читает файл llms.txt или что файл является частью их процесса индексации или обработки. Именно это и заставило нас всё-таки исследовать этот вопрос.
Одной из причин повышенного внимания стало то, что традиционные файлы типа sitemap.xml или robots.txt не всегда идеально решают задачи, связанные с тем, как LLM-системы ищут информацию при генерации ответов. Поэтому хайп вокруг него был вызван отчаянным шагом всё же найти «пилюлю», которая поможет быстро попадать в AI-ответы. Поскольку всем хочется верить в лучшее и находить самые лёгкие пути к цели, то шум вокруг llms.txt активно набирает популярность и дальше.
Джон Мюллер из Google прямо отметил, что по его сведениям серверы сайтов не показывают обращений к llms.txt со стороны крупных AI-систем, сравнивая функциональность этого файла с keywords meta tag (то есть, скорее как дополнительный сигнал, чем как гарантированное средство).
А если напрямую спросить у AI-ассистентов, используют ли они llms.txt, то все как один отрицают это.
Тем не менее, существует факт, который демонстрирует, что тема не оставляет равнодушными другие профильные инструменты. Такими являются Yoast SEO и Rankmath:
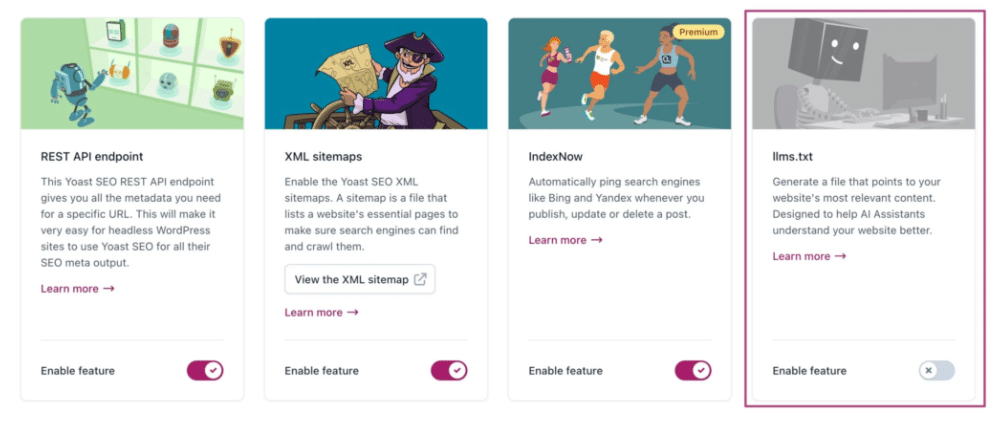
Yoast SEO — это плагин для WordPress, один из самых популярных в мире, который помогает оптимизировать сайты для поисковых систем (SEO). Имеет миллионы пользователей по всему миру, и в июне 2025 года он выпустил функцию, которая автоматически генерирует файл llms.txt, выделяющий самый важный, актуальный контент сайта без сложной технической настройки, одним кликом.
Rankmath — ещё один известный плагин для WordPress. В июле 2025 года он также добавил возможность формирования llms.txt. В Rankmath сделан акцент на кастомизацию: пользователь может вручную указать блоки или страницы, которые должны попасть в файл, а также задать приоритетность контента.
Когда крупные плагины с большой базой сайтов начинают поддерживать такую функцию, это, во-первых, привлекает внимание к ней (в данном случае к llms.txt), а во-вторых, создаёт предпосылки для широкого тестирования, сбора наблюдений и возможной лучшей адаптации стандарта в будущем.
Поэтому мы выдвинули гипотезу по файлам llms.txt и обозначили этот эксперимент как приоритетный. Нашими целями стало определить:
Действительно ли LLM-системы обращаются к llms.txt?
Переходят ли по ссылкам, приведённым в этом файле, даже если эти страницы «сироты» (без внешних или внутренних ссылок)?
Могут ли оптимизированные таким образом страницы попасть в ответы, которые генерирует ChatGPT и другие AI-системы, если предполагается, что модель «прочитала» эти страницы через llms.txt.
Гипотеза и задачи эксперимента
Мы исходим из гипотезы, что LLM-системы могут использовать файл llms.txt для того, чтобы:
Находить ключевые страницы сайта, которые владелец сайта считает важными;
Обращаться по указанным в этом файле URL-адресам даже тогда, когда эти страницы не связаны навигационно с другими частями сайта;
И, как результат, таким образом делать контент с этих страниц доступным для ответов (например, в ответе ChatGPT), даже если режимы «внутренних ссылок» или «обычной индексации» не обеспечивают прямого пути.
Чтобы проверить гипотезу, мы сформулировали следующие задачи:
Выявить, происходит ли обращение к файлу llms.txt со стороны LLM-ботов. То есть: есть ли записи в логах сервера, когда кто-то (возможно, AI-система) пытается получить llms.txt.
Проверить, переходят ли модели и бот-агенты по ссылкам, указанным в этом файле, то есть заходят ли на страницы, которые указаны в llms.txt.
Убедиться, попадают ли оптимизированные страницы в ответы ChatGPT (или других LLM) в случае, если модель имеет доступ к этим страницам через llms.txt. Например, появится ли выдуманное слово, под которое мы оптимизировали страницы, в ответах модели, если модель «посещает» эти страницы через llms.txt.
Методология эксперимента
Чтобы результаты были репрезентативными и имели более широкий смысл, выбраны три сайта, которые существенно отличаются между собой по нескольким ключевым показателям:
Тематика: сайты принадлежат к разным отраслям.
Популярность и трафик: один сайт имеет относительно высокий органический и общий трафик, другой — средний, третий — менее известный, чтобы увидеть, отличается ли поведение по масштабам.
Частота попадания в ответы ChatGPT: выбраны такие сайты, которые уже были упомянуты или использованы в ответах модели (то есть модель «знает» об их существовании, чтобы уменьшить вероятность полной неузнаваемости). Один из таких сайтов – наш luxeo.team, другие два — наши дополнительные проекты, к которым мы имели полный контроль, чтобы следить и ничего не пропустить.
Для выполнения этих задач наша команда предприняла следующие шаги:
Создание файлов llms.txt у каждого из трёх сайтов, используя формат, предложенный на сайте llmstxt.org.
Добавлены в файлы ссылки на «изолированные» страницы от основной навигации сайта, чтобы проверить, сможет ли LLM добраться до них через llms.txt.
Оптимизированы эти «изолированные» страницы под выдуманные слова, чтобы легко отследить, появится ли этот контент в ответах ChatGPT или других LLM, если модель прочитает эти страницы.
Настроен сбор логов сервера (в частности access.log), чтобы иметь возможность отследить:
обращения к файлу llms.txt,
обращения к страницам-сиротам,
источник запросов (User Agent, IP, время), чтобы понять, не автоматические ли или бот-агенты, или, возможно, это LLM-сервисы.
Выполнено несколько проверок в разные временные промежутки и с разных аккаунтов, чтобы исключить влияние кэширования, рандомных задержек или других случайных факторов.
Результаты эксперимента
После нескольких недель мониторинга мы собрали данные с трёх сайтов и провели анализ серверных логов (access.log). Главной задачей было проверить, действительно ли языковые модели (LLM) или связанные с ними боты обращаются к файлу llms.txt, а также происходит ли дальнейшее взаимодействие со страницами. Результаты оказались показательными, но не в пользу гипотезы.
Во-первых, в логах не зафиксировано ни одного обращения к файлам llms.txt от поисковых роботов LLM систем и традиционных поисковых систем.
Боты LLM сканировали страницы сайтов, но ни один не заходил на llms.txt. Это означает, что ни одна система, такая как ChatGPT, Claude, Google Gemini, пока не использует llms.txt как источник данных для парсинга контента.
Во-вторых, не выявлено никаких переходов на специально созданные страницы. Поскольку эти страницы не имели других путей доступа, их единственным «выходом в свет» было включение в llms.txt. Отсутствие посещений доказывает, что этот файл на данный момент не является сигналом для обхода контента.
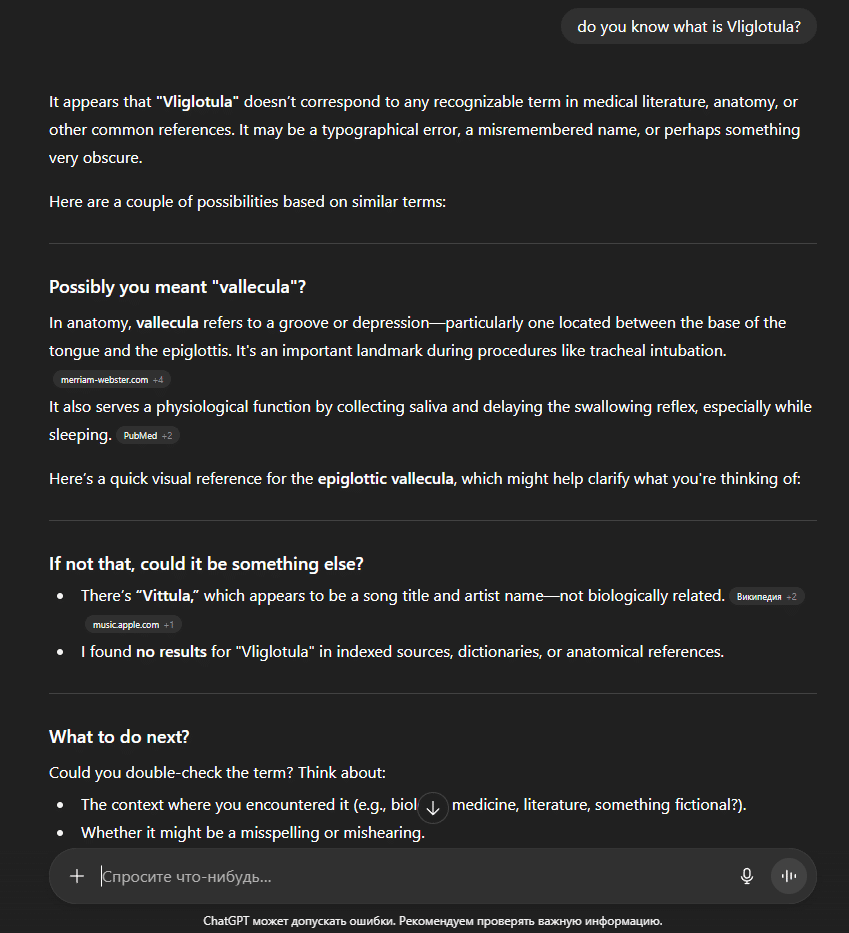
В-третьих, выдуманные слова, которые мы использовали для оптимизации страниц-сирот (например, Vliglotula на одном из сайтов), не появились в ответах ChatGPT во время дополнительных тестов. Это ещё раз подтвердило, что модель не имела доступа к этим страницам и не получила с них никакой информации.
Отдельно была проведена дополнительная проверка: обращаются ли LLM-системы к sitemap.xml, ведь этот файл является стандартным инструментом и по сути llms.txt его дублирует в каком-то смысле. В результате удалось зафиксировать некоторую активность.
Были зафиксированы обращения от Claude к sitemap.xml, что может свидетельствовать о минимальном тестировании или использовании этого файла как источника информации. От других AI-ассистентов в логах не было найдено ни одного обращения к sitemap.xml.
Таким образом, все основные пункты проверки дали отрицательные результаты, о чём мы имели подозрения, но всё равно были удивлены.
Выводы эксперимента
Результаты эксперимента указывают на то, что файл llms.txt пока не используется LLM-системами для сбора информации о сайтах. Это подтверждает первоначальные сомнения, которые мы имели ещё на этапе планирования: слишком много факторов свидетельствовало, что эта инициатива скорее является теоретической, чем реально внедрённой практикой.
Особенно важным является факт, что даже при создании оптимизированных страниц под уникальное выдуманное слово ни одна LLM-система не использовала этот контент в своих ответах. В будущем возможно внедрение новых механизмов, но сегодня подтверждения работы llms.txt нет.
Таким образом, эксперимент доказывает, что llms.txt на данном этапе существует скорее как «предложение к обсуждению», а не как инструмент, который реально влияет на взаимодействие LLM с сайтами.
Заключение и дальнейшие планы
Не всё, что активно обсуждают в интернете, соответствует реальности. Проведённый эксперимент показал, что llms.txt на данный момент не имеет практической пользы и не влияет на индексацию или использование контента в ответах LLM. Как дополнительную услугу с перспективой на будущее это можно упоминать клиентам, но делать ставку на него сейчас нецелесообразно, и выделять на это бюджеты клиентов также, давая пустые обещания. Но сама концепция имеет потенциал развиться в течение года, из-за активного внимания.
Дальнейшие гипотезы для тестирования, результаты которых мы уже готовим к публикации:
Повышают ли ссылки с сайтов (страниц), которые цитируют LLM, видимость в ответах ИИ.
Учитывают ли LLM отзывы с разных ресурсов о продуктах, товарах или услугах при формировании ответов.
Дмитрий Ковшун является основателем компании Luxeo Team – SEO Outsourcing Company. Как ведущий специалист в отрасли, он признан экспертом в области SEO-продвижения сайтов. С многолетним опытом и глубоким пониманием этой области, Дмитрий продолжает способствовать успеху и инновациям в SEO-стратегиях, помогая бизнесам достигать их онлайн-целей.