Over the past few months, the idea that having an llms.txt file almost guarantees that your content will be included in responses from Large Language Models (LLMs) has been actively promoted. It’s been featured in blogs, recommended by niche influencers, and even included in service offerings by companies providing AEO (AI Engine Optimization) services. But is this truly the case?
The llms.txt file is positioned as a standard that provides LLM systems with a map of a website’s important content. However, there’s currently no confirmation that AI models actually use it. We’ve seen a lot of information about it, but no real evidence that llms.txt works.
Here are a few facts about the file and why it has become a topic of discussion:
John Mueller from Google explicitly stated that, to his knowledge, site server logs do not show requests for llms.txt from major AI systems. He compared the file’s functionality to a keywords meta tag (i.e., more of a supplementary signal than a guaranteed method).
And if you ask AI assistants directly whether they use llms.txt, they will all deny it.

Despite the lack of official support, the topic is not being ignored by other professional tools. The most notable examples are Yoast SEO and Rankmath.
Yoast SEO is one of the world’s most popular WordPress plugins, helping to optimize sites for search engines. It has millions of users worldwide, and in June 2025, it released a feature that automatically generates an llms.txt file, highlighting the most important and relevant site content with a single click and no complex technical setup.
Rankmath is another well-known WordPress plugin. In July 2025, it also added the ability to create an llms.txt file. Rankmath emphasizes customization, allowing users to manually specify which blocks or pages should be included in the file and to set content priority.
When large plugins with a massive user base begin to support such a feature, it, first, draws attention to it (in this case, llms.txt), and second, creates the groundwork for widespread testing, data collection, and potential better adaptation of the standard in the future.
This led us to form a hypothesis about llms.txt files and designate this experiment as a priority. Our goals were to determine:
Our hypothesis is that LLM systems might use the llms.txt file to:
To test this hypothesis, we formulated the following tasks:
To ensure the results were representative and had broader meaning, we selected three websites that differ significantly in several key metrics:
To perform these tasks, our team took the following steps:
After several weeks of monitoring, we collected data from the three sites and analyzed the server logs. The main task was to check if LLMs or their associated bots were truly accessing the llms.txt file and if there was any subsequent interaction with the pages. The results were revealing, but they did not support our hypothesis.
First, the logs recorded no requests for llms.txt files from LLM system bots or traditional search engines.

LLM bots scanned the sites’ pages, but not a single one accessed llms.txt. This means that no system, such as ChatGPT, Claude, or Google Gemini, currently uses llms.txt as a source for content parsing.
Second, we found no visits to the specially created pages. Since these pages had no other way of being accessed, their only “way out into the world” was being included in llms.txt. The lack of visits proves that this file is not currently a signal for crawling content.
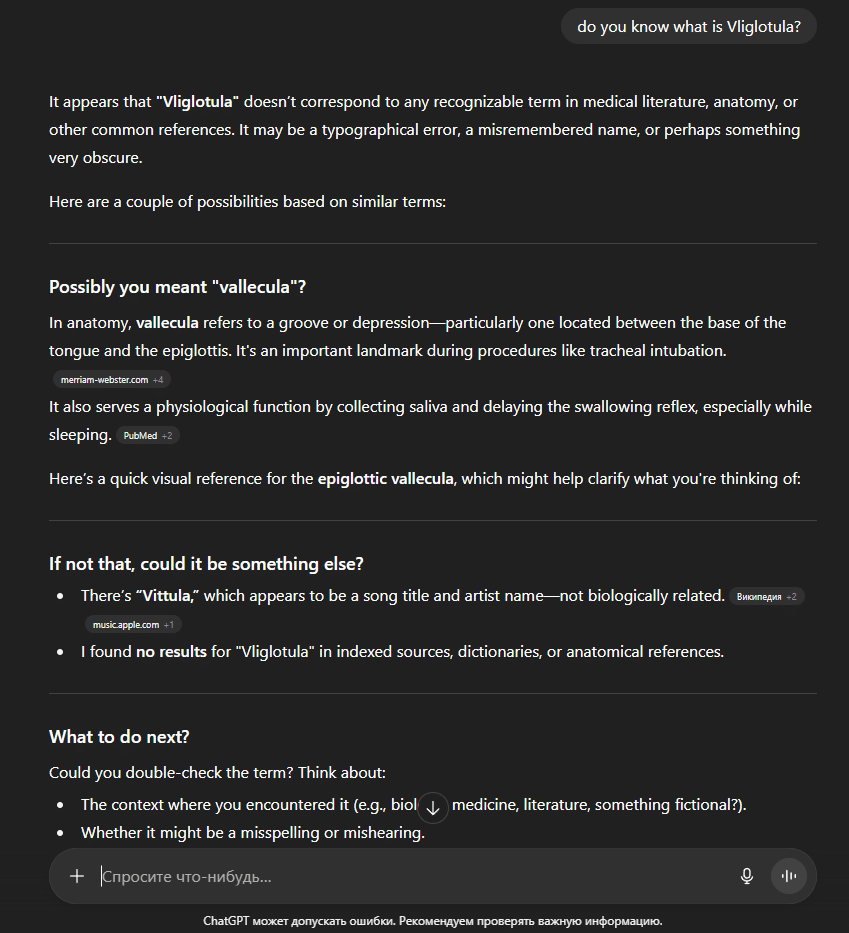
Third, the made-up words we used to optimize the orphan pages (e.g., “Vliglotula” on one of the sites) did not appear in ChatGPT’s responses during additional tests. This further confirmed that the model did not have access to these pages and did not get any information from them.
Separately, we conducted an additional check to see if LLM systems accessed sitemap.xml, as this file is a standard tool and llms.txt essentially duplicates it in some sense. As a result, we were able to record some activity. We observed requests from Claude to sitemap.xml, which may indicate minimal testing or use of this file as a source of information. No requests to sitemap.xml from other AI assistants were found in the logs.

Thus, all the main points of our check yielded negative results, which we suspected, but were still surprised to confirm.
The experiment results indicate that the llms.txt file is not yet being used by LLM systems to gather information about websites. This confirms the initial doubts we had during the planning stage: too many factors suggested that this initiative was more theoretical than a genuinely implemented practice.
The fact that not a single LLM system used the content from the optimized pages—even those based on a unique made-up word—is especially important. The implementation of new mechanisms is possible in the future, but today there is no confirmation that llms.txt works.
Therefore, the experiment proves that llms.txt at this stage exists more as a “proposal for discussion” than as a tool that genuinely influences LLM interaction with websites.
Not everything that is actively discussed on the internet corresponds to reality. The experiment showed that llms.txt currently has no practical use and does not influence the indexing or use of content in LLM responses. It can be mentioned to clients as an additional service with potential for the future, but it is not advisable to rely on it now or allocate client budgets for it by making empty promises. However, the concept itself has the potential to develop within a year due to active attention.
Our further hypotheses for testing, the results of which we are already preparing for publication, are:
CONTACTS
Promotion application: order@luxeo.team
For partnership: partner@luxeo.com.ua
Thanks for your application!
Our specialists will contact you within 24 hours