Реальне значення llms.txt файлу для LLM систем: Результати незалежного тесту AI відповідей №3
24 Вересня 2025129 перегляди
1 хв.
Dmytro Kovshun
Редактор
Зміст
В останні місяці стала активно розкручуватися теза, що наявність llms.txt майже гарантовано призводить до того, шо ви потрапите у відповіді в LLM (Large Language Models). Це пишуть в блогах, це рекомендують нішеві інфлюенсери, і це включають в оффер для клієнтів компанії, які пропонують АЕО послуги. Але чи справді це так?
Llms.txtпозиціонований як стандарт, який надає LLM-системам мапу важливого вмісту сайту. Але наразі немає підтверджень, чи справді АІ моделі його використовують. Ми бачили багато інформації, але не бачили реальні факти того, що llms.txt працює.
Кілька фактів про файл і чому про нього заговорили:
llms.txt — це текстовий файл, розміщений в корені домену (наприклад, https://example.com/llms.txt), який за форматом Markdown чи схожими помітками містить перелік URL-адрес або описів сторінок, які власники сайту вважають “ключовими”, “якісними” та такими, що варто вказати LLM-системам як пріоритетний вміст.
Ініціатива llms.txt поки що є пропозиціює стандарту; вона не є офіційно підтвердженою всесвітньо використовуваною практикою з боку найбільших мовних моделей чи компаній, але тим не менше активно обговорюється в SEO-спільноті. За даними інтерв’ю й публічних заяв, жоден із великих постачальників мовних моделей (OpenAI / ChatGPT, Anthropic / Claude, Google / Gemini тощо) офіційно не підтвердив, що він читає файл llms.txt або що файл є частиною їх процесу індексації чи обробки. Саме це і змусило нас все ж токи дослідити це питання.
Однією з причин підвищеної уваги стало те, що традиційні файли типу sitemap.xml чи robots.txt не завжди ідеально вирішують завдання, пов’язані з тим, як LLM-системи шукають інформацію під час генерації відповідей. Тому хайп навколо нього був визваний відчайдушним кроком все ж таки знайти “пігулку” яка допоможе швидко потрапляти в АІ відповіді. Оскільки всім хочеться вірити в краще і знаходити найлегші шляхи до цілі, то шум навколо llms.txt активно набуває популярності і надалі.
Джон Мюллер з Google прямо зазначив, що на його відомості сервера сайтів не показують звернень до llms.txt від сторін великих AI-систем, порівнюючи функціональність цього файлу з keywords meta tag (тобто, радше як додатковий сигнал, ніж як гарантований засіб).
А якщо напряму запити у АІ асистентів, чи використовують вони llms.txt, то всі як один заперечать це.
Проте існує факт, який демонструє, що тема не лишає байдужими інші профільні інструменти. Такими є Yoast SEO та Rankmath:
Yoast SEO — це плагін для WordPress, один із найпопулярніших у світі, який допомагає оптимізувати сайти для пошукових систем (SEO). Має мільйони користувачів по всьому світу, і у червні 2025 року він випустив функцію, яка автоматично генерує файл llms.txt, що виділяє найважливіший, актуальний контент сайту без складної технічної настройки, одним кліком.
Rankmath — ще один відомий плагін для WordPress. У липні 2025 року він також додав можливість формування llms.txt. У Rankmath зроблено акцент на кастомізацію: користувач може вручну вказати блоки або сторінки, які повинні потрапити у файл, а також задати пріоритетність контенту.
Коли великі плагіни із великою базою сайтів починає підтримувати таку функцію, це по-перше, привертає увагу до неї (в цьому випадку llms.txt), а по-друге, створює передумови для широкого тестування, збору спостережень і можливої кращої адаптації стандарту в майбутньому.
Тож ми висунули гіпотезу по файлам llms.txt і позначили цей експеримент як пріоритетний. Нашими цілями стало визначити:
Чи справді LLM-системи звертаються до llms.txt?
Чи переходять за посиланнями, наведеними у цьому файлі, навіть якщо ці сторінки “сироти” (без зовнішніх чи внутрішніх посилань)?
Чи оптимізовані таким чином сторінки можуть потрапити у відповіді, які генерує ChatGPT та інші AI системи, якщо передбачається, що модель “прочитала” ці сторінки через llms.txt.
Гіпотеза та завдання експерименту
Ми виходимо з гіпотези, що LLM-системи можуть використовувати файл llms.txt для того, щоб:
знаходити ключові сторінки сайту, які власник сайту вважає важливими;
звертатися за вказаними в цьому файлі URL-адресами навіть тоді, коли ці сторінки не пов’язані навігаційно з іншими частинами сайту;
і, як результат, таким чином робити контент із цих сторінок доступним для відповідей (наприклад, у відповіді ChatGPT), навіть якщо режими “внутрішніх посилань” чи “звичайної індексації” не забезпечують прямого шляху.
Щоб перевірити гіпотезу, ми сформулювали такі завдання:
Виявити, чи відбувається звернення до файлу llms.txt з боку LLM-ботів. Тобто: чи є записи в логоах серверу, коли хтось (можливо, AI-система) намагається отримати llms.txt.
Перевірити, чи моделі та бот-агенти переходять за посиланнями, зазначеними в цьому файлі, тобто чи заходять на сторінки, які вказані у llms.txt.
Переконатися, чи оптимізовані сторінки потрапляють у відповіді ChatGPT (чи інших LLM) у випадку, якщо модель має доступ до цих сторінок через llms.txt. Наприклад, чи з’явиться вигадане слово, під яке ми оптимізували сторінки, у відповідях моделі, якщо модель “відвідує” ці сторінки через llms.txt.
Методологія експерименту
Щоб результати були репрезентативними і мали ширший сенс, обрано три сайти, які суттєво відрізняються між собою за кількома ключовими показниками:
Тематика: сайти належать до різних галузей.
Популярність і трафік: один сайт має відносно високий органічний та загальний трафік, інший — середній, третій — менш відомий, щоб побачити, чи відрізняється поведінка по масштабах.
Частота потрапляння у відповіді ChatGPT: обрані такі сайти, які вже були згадані чи використані у відповідях моделі (тобто модель “знає” про їх існування, щоб зменшити ймовірність повної невпізнанності).
Один із таких сайтів – наш luxeo.team, інші два – наші додаткові проєкти, до яких ми мали повний контроль, щоб слідкувати і нічого не пропустити.
Для виконання цих завдань наша команда зробила такі кроки:
Створення файлів llms.txt у кожного з трьох сайтів, використовуючи формат, запропонований на сайті llmstxt.org.
Додано у файли посилання на “ізольовані” сторінки від основної навігації сайту, щоб перевірити, чи зможе LLM дістатися до них через llms.txt.
Оптимізовано ці “ізольовані” сторінки під вигадані слова, щоб легко відслідкувати, чи з’явиться цей контент у відповідях ChatGPT або інших LLM, якщо модель прочитає ці сторінки.
Налаштовано збір логів серверу (зокрема access.log), щоб мати можливість відслідкувати:
звернення до файлу llms.txt,
звернення до сторінок-сиріт,
джерело запитів (User Agent, IP, час), щоб зрозуміти, чи не автоматичні чи бот-агенти, чи можливо це LLM-сервіси.
Виконано кілька перевірок у різні часові проміжки і з різних акаунтів, щоб виключити вплив кешування, рандомних затримок, чи інших випадкових факторів.
Результати експерименту
Після кількох тижнів моніторингу ми зібрали дані з трьох сайтів і провели аналіз серверних логів (access.log). Головним завданням було перевірити, чи дійсно мовні моделі (LLM) або пов’язані з ними боти звертаються до файлу llms.txt, а також чи відбувається подальша взаємодія з сторінками. Результати виявилися показовими, але не на користь гіпотези.
По-перше, у логах не зафіксовано жодного звернення до файлів llms.txt від пошукових роботів LLM систем та традиційних пошкових систем.
Боти LLM сканували сторінки сайтів, але жоден не заходив на llms.txt. Це означає, що жодна система як то ChatGPT, Claude, Google Gemini наразі не використовує llms.txt як джерело даних для парсингу контенту.
По-друге, не виявлено жодних переходів на спеціально створені сторінки. Оскільки ці сторінки не мали інших шляхів доступу, їх єдиним “виходом у світ” було включення до llms.txt. Відсутність відвідувань доводить, що цей файл наразі не є сигналом для обходу контенту.
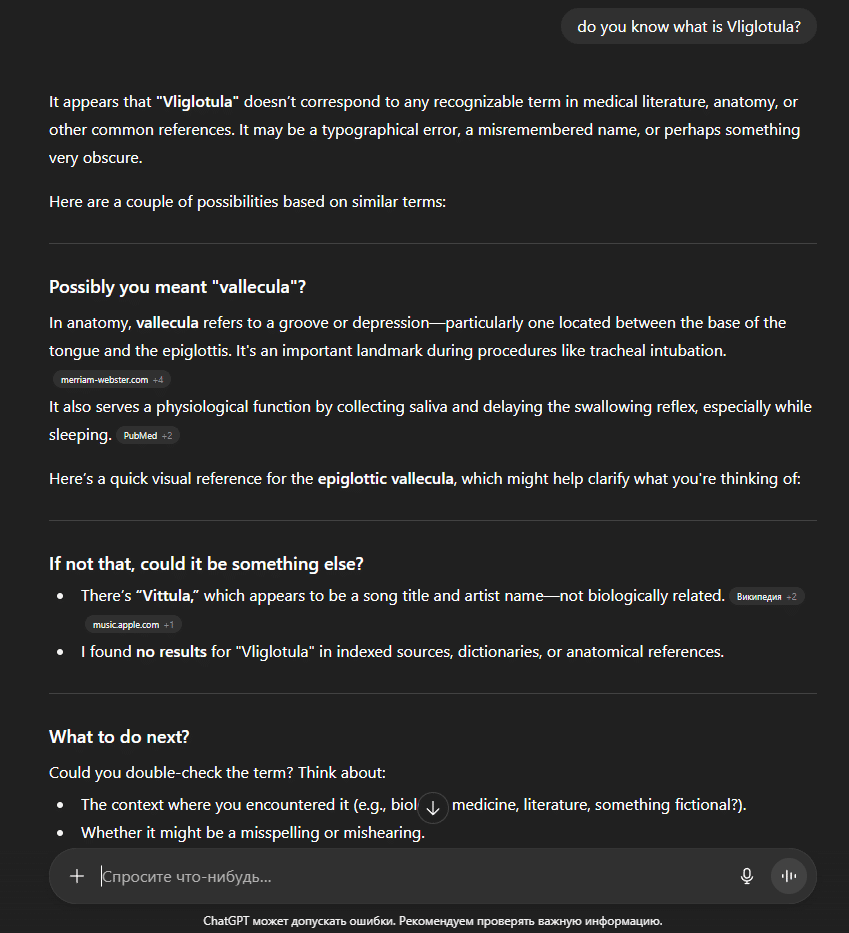
По-третє, вигадані слова, які ми використали для оптимізації сторінок-сиріт (наприклад, Vliglotula на одному з сайтів), не з’явилися у відповідях ChatGPT під час додаткових тестів. Це ще раз підтвердило, що модель не мала доступу до цих сторінок і не отримала з них жодної інформації.
Окремо було проведено додаткову перевірку: чи звертаються LLM-системи до sitemap.xml, адже цей файл є стандартним інструментом і по суті llms.txt його дублює в якомусь сенсі. У результаті вдалося зафіксувати деяку активність.
Були зафіксовані звернення від Claude до sitemap.xml, що може свідчити про мінімальне тестування або використання цього файлу як джерела інформації. Від інших АІ асистентів у логах не було знайдено жодного звернення до sitemap.xml.
Таким чином, усі основні пункти перевірки дали негативні результати, про що ми мали підозри, але все одно були здивовані.
Висновки експерименту
Результати експерименту вказують на те, що файл llms.txt поки що не використовується LLM-системами для збору інформації про сайти. Це підтверджує початкові сумніви, які ми мали ще на етапі планування: занадто багато факторів свідчило, що ця ініціатива радше є теоретичною, ніж реально впровадженою практикою.
Особливо важливим є факт, що навіть при створенні оптимізованих сторінок під унікальне вигадане слово жодна LLM-система не використала цей контент у своїх відповідях. У майбутньому можливе впровадження нових механізмів, але сьогодні підтвердження роботи llms.txt немає.
Таким чином, експеримент доводить, що llms.txt на даному етапі існує радше як “пропозиція до обговорення”, а не як інструмент, що реально впливає на взаємодію LLM із сайтами.
Заключення та подальші плани
Не все, що активно обговорюють в інтернеті, відповідає реальності. Проведений експеримент показав, що llms.txt наразі не має практичної користі і не впливає на індексацію чи використання контенту у відповідях LLM. Як додаткову послугу з перспективою на майбутнє це можна згадувати клієнтам, але робити ставку на нього зараз недоцільно, і виділяти на це бюджети клієнтів також, надаючи порожні обіцянки. Але сама концепція має потенціал розвинутися протягом року, через активну увагу.
Подальші гіпотези для тестування, результати яких ми вже готуємо до публікації:
Чи підвищують посилання з сайтів (сторінок), які цитують LLM, видимість у відповідях ШІ.
Чи враховують LLM відгуки з різних ресурсів про продукти, товари чи послуги при формуванні відповідей.
Дмитро Ковшун є засновником компанії Luxeo Team – SEO Outsourcing Company. Як провідний фахівець у галузі, він визнаний експертом у сфері SEO-просування сайтів. З багаторічним досвідом і глибоким розумінням цієї галузі, Дмитро продовжує сприяти успіху та інноваціям у стратегіях SEO, допомагаючи бізнесам досягати їхніх онлайн-цілей.